
I was once asked if federated wiki was a product ready to be used or just an experiment. I couldn't deny the latter but don't consider it a weakness. Here I transcribe an explanation. matrix ![]()
We describe the admittedly confusing introduction of new aids for collaborative interpretation of texts.
See also Experimental Epistemology
# Neighbors
Federated wiki promotes sharing pages as a creative commons where a lower-case coincidence of page titles implies some cooperation. This would seem to create unwanted interference were it not for our other rule that each author writes to their own wiki site.
The portion of the commons in view is called the neighborhood and that grows for a given browser tab as one browses. The source of every page is identified by the colored square, the Flag, in the top left corner. If you click that flag then the browser tab becomes focused on that page as it appears on its site with the neighborhood reduced to sites in that page's history.
# Coincidence
What we write is automatically contributed to the commons as prescribed by the SA, share alike, clause in the license. This works best when page titles are chosen carefully. For example, today is the last day of our vacation here in Phoenix. We'll breakfast at the Waffle House, visit the Pueblo Grande historical site and the proceed to the PHX airport.
See Pueblo Grande
I've already made a page for today which I could have titled 2023-03-20. If Karen and I were both travel blogging then that might be exactly the coincidence that we would want to tell our respective reasons for choosing Waffle House. (There are reasons.) But instead I chose to title what is probably the most interesting event today Pueblo Grande. A coincidence here will be much more telling.
# Ghosts
Not all pages in the browser lineup correspond to pages in federation servers. Search results are (optionally) presented in a generated page of Reference items which can be scrolled, copied from or save as is with fork. Search generates a title for this temporary page which is not (yet) published on any server.
We are finding many more reasons to generate pages and often settle for temporarily useful names using some fact present in the generation but not likely to lead to cooperative coincidence. We emphasize the ghostly insubstantial nature of these pages by making them transparent. The transparent nature is more obvious when they appear over other content or on sites with more textured background.
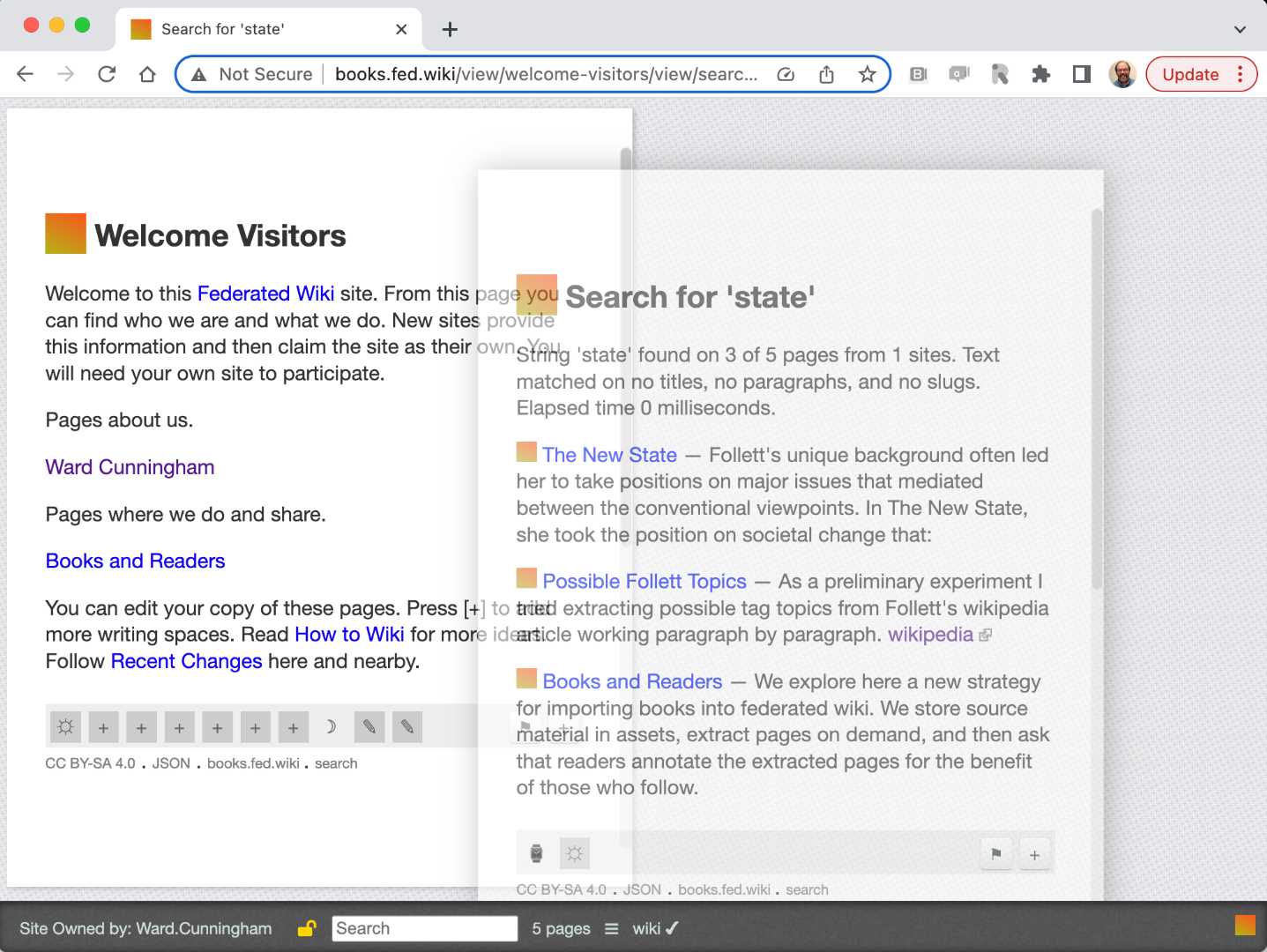
A generated but not saved page appears ghostly transparent.
# Workflow
As it has become increasingly easy to write small html scripts that interact with the lineup we find many more reasons to generate ghost pages as part of our workflows. Because scripts flow freely through the federation we don't grant to them the power to update content on our own sites without our case by case approval. For content most conveniently expressed as wiki markup we use ghost pages.
For other content that is more conveniently kept in files, often json files, we allow scripts to download to the user's own filesystem from which they can upload back into wiki assets with drag and drop. Some browsers make this convenient with easy access to recent downloads without leaving the web page.
We've found that workflows will often involve two or three steps that with time and experience might be shortened to one or two steps, but still using steps that are more generic manipulations of the wiki than steps designed for the problem at hand. This runs counter to "good" interaction design but might someday be recognized as worthy by the design community.
# Tagging
With regards to tagging content on wiki pages we are at the exploratory phase where even basic operations take two or three workflow steps. This gives us lots of latitude for invention and I have indulged myself with a bit of it. In summary: Site Survey is based on html scripts with no special powers other than available to any script floating around the federation.
Site Survey was coded to use more application specific pluggable modules we calling Probes. A survey "launch" creates a page, necessarily a ghost page, with information within it to maintain and update results from one probe for one site. This is the raw data which a probe can render in a form most useful for double checking the accuracy of probes and the content probed. To this we add more application specific scripts which can be as varied as the applications they support.
My most recent work has been exploring tagging through the creation of a probe for a tag syntax that would fit gracefully into the ways we already write in wiki. I support the viewing of tag survey results with another script called the tag aggregator. The aggregator reads a list of raw survey results and constructs a variation of a tag cloud where tag words are listed in numbered sections based on their frequency in the corpus.
More common tag clouds use various font sizes in a cleverly packed square of words going every which way. We have not ruled this out. We just need another script.
# Lateral
This brings us finally to the point where we can explain "lateral tags". The probe finds strings of words at the end of paragraphs distinguished by the newly made up tag symbol >> before the words. The probe records these words as written so long as they are lower case, properly spaced and at the end of a Paragraph or Markdown item. It is the tag aggregator that attaches significance to individual words.
If we wrote ">> world order" then the aggregator sees "world" and "order" without regard to the order that they appeared in the raw record. A different aggregator could do otherwise. Continuing my inclination to invent new things I added to this particular aggregator the notion that a paragraph tagged with "world order" would be making some possible association between the individual words "world" and "order". Now, If "world" were shown to appear in the corpus 9 times, and one were to click that tag, they could expect to see 9 paragraphs in the ghost page result with the title "world x 9" summarizing a few facts leading to the creation of the ghost page.
The same script that creates this page notices that the raw tags encounter imply some association between world and order. Another paragraph might be about baseball and be appropriately tagged with "world series". My logic then concludes that "order" and "series" are laterally related. While generating the expected "world x 9" ghost page my script adds any paragraphs that contain tags for "order" and "series" that have not already been mentioned on the page.
Should the corpus contain mathematical content tagged "taylor series" this would be found as lateral material. The connection is by tag associations. In this case from "world" to "world order" to "world series" to "taylor series". Here we will have traveled latterly from government to sports to mathematics but only because all were present in the corpus we have chosen. This is the reward we expect from our selective participation in the commons.